2024 New Year, New Number: New Benchmarks Show Dragonfly Achieves 6.43 Million Ops/Sec on an AWS Graviton3E Instance
With the advancements of cutting-edge hardware, Dragonfly reaches 6.43 million ops/sec on a single `c7gn.16xlarge` instance.
January 24, 2024

Introduction
Last year, we published benchmark results showing that Dragonfly can achieve 4 million ops/sec on an AWS c6gn.16xlarge instance. To put that into perspective, it's like every person in Los Angeles (as of 2020, roughly 3.9 million residents) asking Dragonfly a question, and Dragonfly answers instantly, all within that single second.
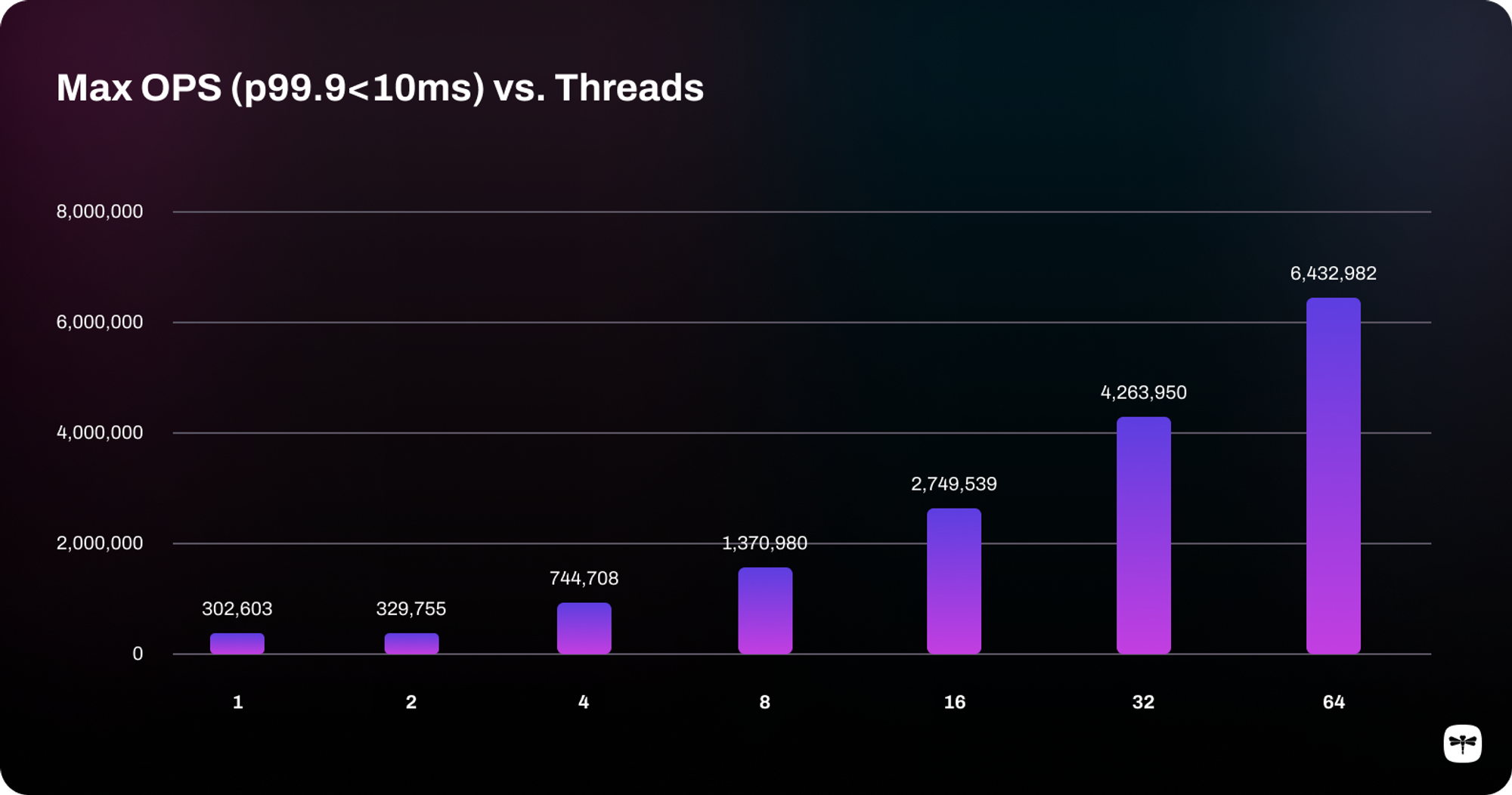
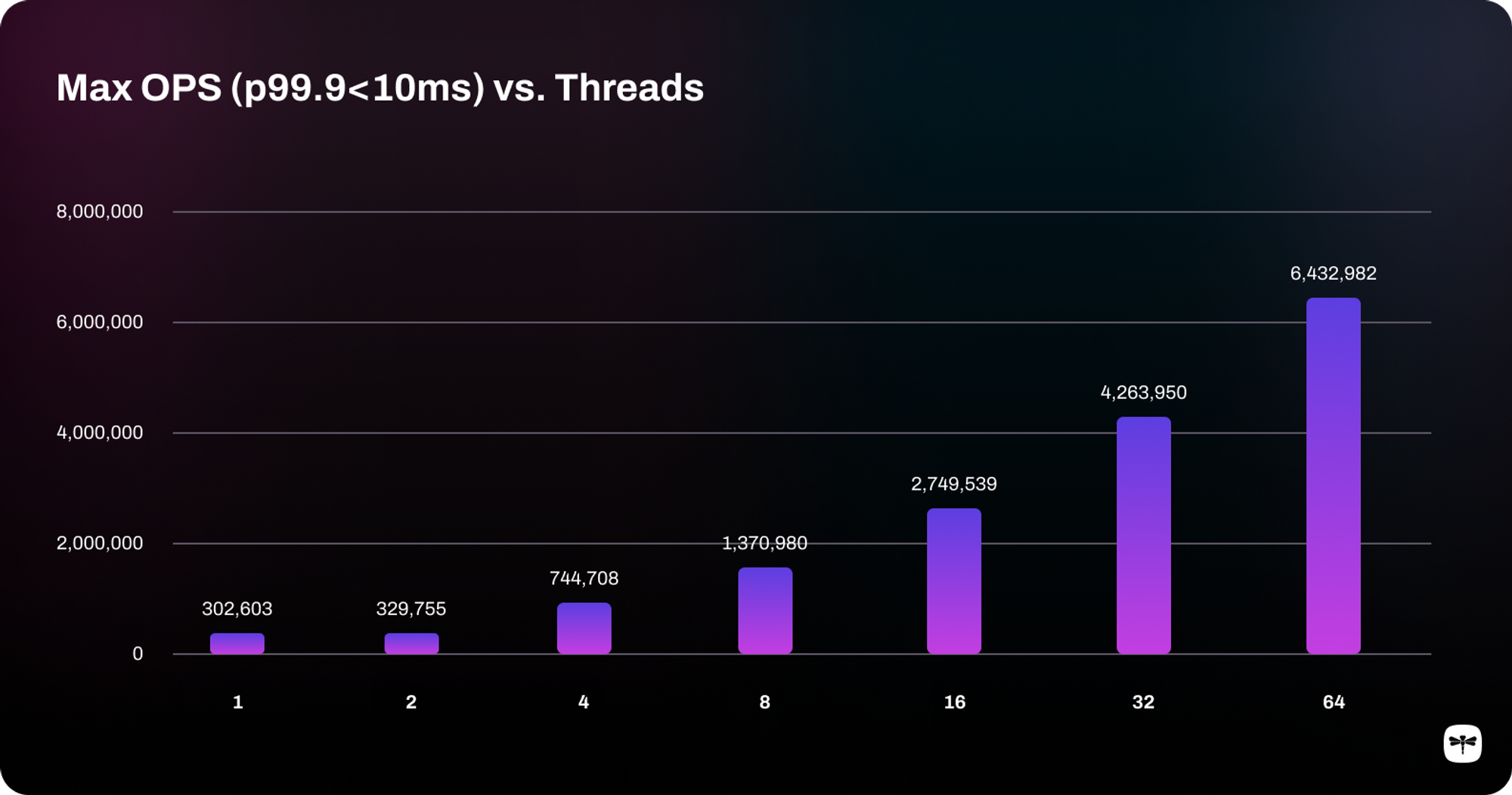
However, we have exciting news from our latest benchmarks: by operating on a new AWS c7gn.16xlarge single instance, we've now achieved 6.43 million ops/second with Dragonfly.
Number of Dragonfly Threads | Max Ops/Second (P99.9 < 10ms) |
|---|---|
1 | 302,603 |
2 | 329,755 |
4 | 744,708 |
8 | 1,370,980 |
16 | 2,749,539 |
32 | 4,263,950 |
64 | 6,432,982 |
Beyond the Number - Dragonfly Advances with Hardware
This latest benchmark achievement goes beyond just the number. It's about how Dragonfly leverages hardware advancements to boost performance. Normally, a 60.75% increase in throughput — going from 4 million to 6.43 million operations per second — might suggest major code optimizations or architectural changes. But that's not the case for Dragonfly.
First, let's take a look at the hardware advancements. At the beginning of 2023, we used the c6gn.16xlarge instance for throughput benchmarking. Around June 2023, AWS announced the c7gn series, which are powered by ARM-based AWS Graviton3E processors that deliver up to 25% better performance over Graviton2-based c6gn instances. They are ideal for a large variety of compute-intensive workloads, including in-memory data stores like Dragonfly. Network-wise, the c7gn instances deliver up to 200Gbps of network bandwidth and up to 2x higher packet processing performance than the previous-generation c6gn instances. Below is a quick comparison of the two instances. It is notable that the price of the c7gn instance is ~44% higher than the c6gn instance, but the Dragonfly throughput gain is ~60.75%, which demonstrates how cost-efficient Dragonfly is.
c6gn.16xlarge | c7gn.16xlarge | |
|---|---|---|
vCPUs | 64 | 64 |
Memory | 128GiB | 128GiB |
Physical Processor | AWS Graviton2 Processor | AWS Graviton3 Processor |
Clock Speed (GHz) | 2.5 | 2.6 |
Network Performance (Gibps) | 100 | 200 |
Price (us-east-1, January 2024) | $2.765/hour | $3.994/hour |
Over the past year, we've certainly refined Dragonfly's performance. For instance, we enhanced the performance of the MGET command, improved the overall performance and memory efficiency of the Sorted-Set data type, optimized multiple aspects to get 30x throughput with BullMQ, and many more. Yet, the core design and architecture remain unchanged. And this is key: Dragonfly's architecture is designed to scale vertically with hardware improvements. It's not just about tweaking the codebase for better throughput; it's about the fundamental architecture that inherently capitalizes on the evolving capabilities of the hardware it runs on. Thus, we are confident to say that the existing Dragonfly codebase, robust and efficient as it is, is ready to see further performance gains as hardware advances in the future.
One of the key design elements that allows Dragonfly to take advantage of advancements in hardware is its multi-threaded shared-nothing architecture. Below, we will dive deeper into how this architecture automatically unlocks performance from advancements in hardware.
Dragonfly Architecture Overview
Dragonfly runs as a single process with multiple threads, and it is designed to run on multi-core servers without any special configurations or optimizations. Dragonfly's in-memory data store keyspace is sharded into N parts, where N is less than or equal to the number of CPU logical cores in the system. Each shard is owned and managed by a single Dragonfly thread, establishing a shared-nothing architecture.
To put it simply, Dragonfly's thread-per-core model and shared-nothing architecture make it like an already perfectly orchestrated group of Redis processes without the overhead of cluster management. This is why Dragonfly can automatically achieve higher throughput performance when put on more powerful machines: more Dragonfly threads can be created if there are more CPU logical cores available, and when each core is more powerful, each Dragonfly thread can inherently handle more operations per second.
In the meantime, atomicity is crucial for Dragonfly key-value operations. It is not possible to use mutexes or spinlocks to orchestrate threads at the rates described above, as they would immediately cause contention. Much like a busy high-speed multi-lane road being regulated by a traffic light that only permits one car to pass at a time, the presence of such a bottleneck leads to considerable congestion. To provide atomicity guarantees for multi-key operations in the shared-nothing architecture, we incorporate recent academic research. Specifically, we've based our transactional framework for Dragonfly on the paper "VLL: a lock manager redesign for main memory database systems". By adopting a shared-nothing architecture and VLL, we can achieve multi-key operations without relying on mutexes or spinlocks.
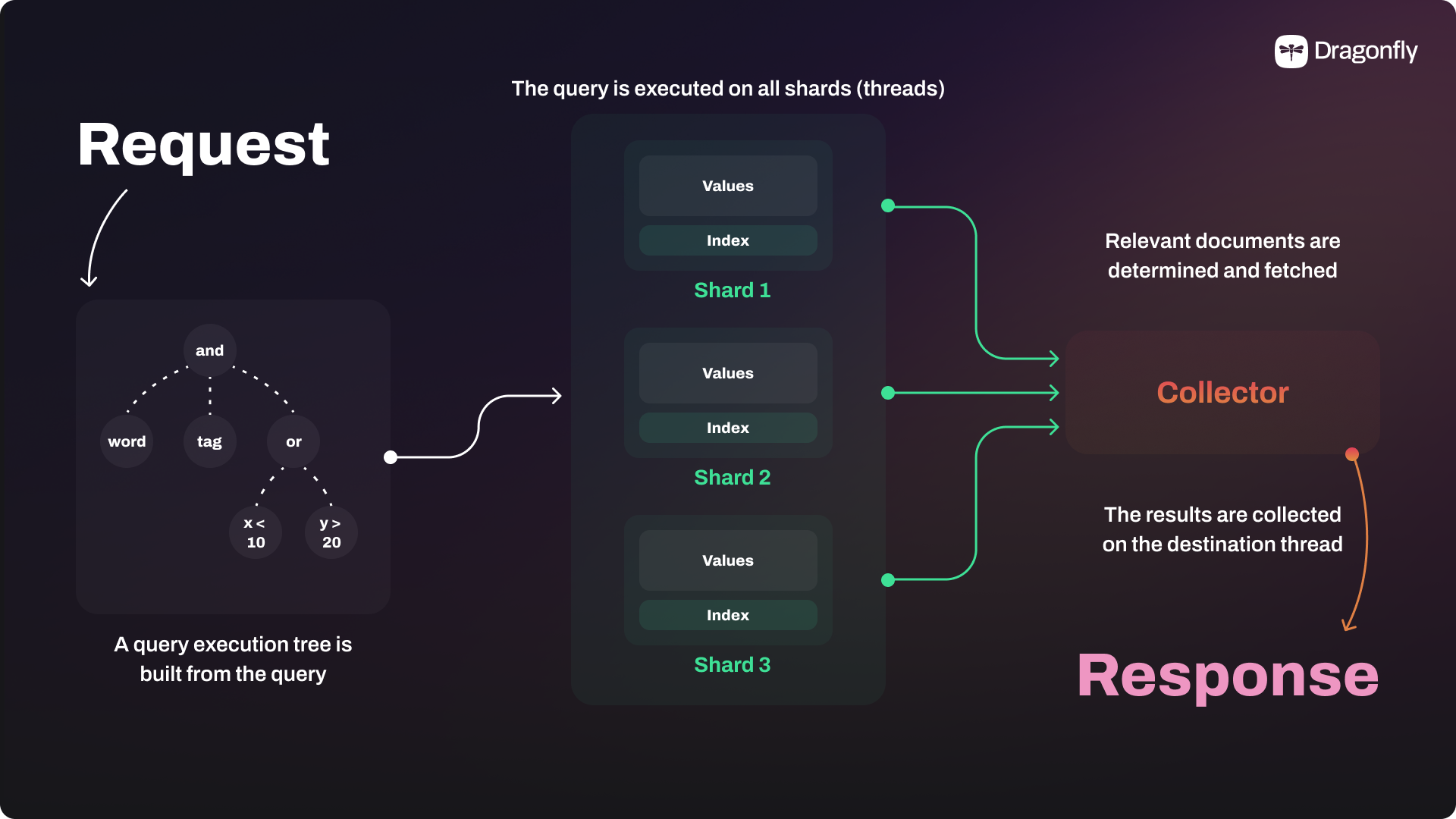
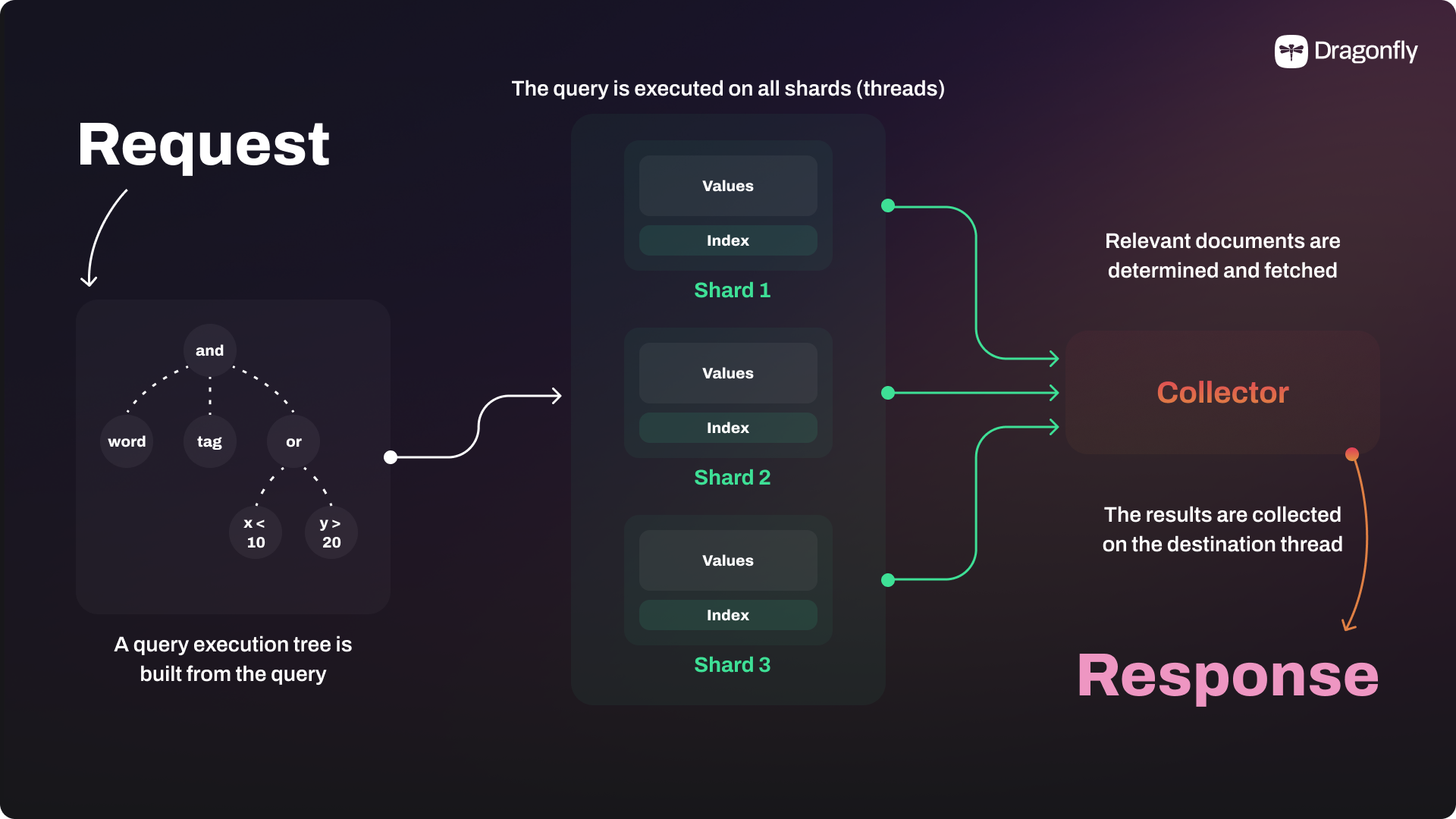
Let's take a look at some examples. When Dragonfly receives a simple GET or SET command, it will first calculate the hash of the key and then find the corresponding shard. Then the data manipulation will be performed by the specific Dragonfly thread that owns the shard, while other threads are free to process more commands without heavy congestion. A more complex example would be a Dragonfly Search command, which is a multi-key operation. When Dragonfly receives a search command, it will first parse the command to build a query execution tree. Then Dragonfly descends to all the threads, where each thread has a separate index that knows about all the indexed values in the corresponding shard. Multiple threads will execute the query tree efficiently in parallel, and the results will be merged and returned to the client. The shared-nothing architecture and VLL guarantee that the multi-key operations are atomic, consistent, and highly efficient.
How to Repeat the Benchmark Results
As shown in the table and chart above, Dragonfly is able to reach 6.43 million ops/sec with 64 Dragonfly threads on a single instance, while maintaining a P50 latency of 0.3ms, a P99 latency of 1.1ms, and a P99.9 latency of 1.5ms. The benchmark was conducted with multiple Dragonfly thread configurations and memtier_benchmark thread & connection configurations, and we take the maximum ops/sec value with a P99.9 latency of less than 10ms as the final result set. Here are the detailed steps to repeat the benchmark results:
- Use two AWS
c7gn.16xlargeinstances, one for the server (i.e., Dragonfly) and one for the client (i.e., thememtier_benchmarkCLI). Thec7gn.16xlargeinstance has 64 vCPUs, 128GiB memory, and is equipped with the AWS Graviton3 processor. - Make sure the network configuration between the two instances is correct, so that the client can connect to the server.
- For the Dragonfly server, use the following configuration arguments:
--proactor_threads=64, which specifies the number of Dragonfly threads. - Fill the Dragonfly server with 10 million keys, to simulate a data store that is in use.
dragonfly$> DEBUG POPULATE 10000000 key 550- Use the following
memtier_benchmarkcommand on the client instance to perform benchmark and collect results:
$> memtier_benchmark -p 6380 --ratio=<get_set_ration> \ # 1:0 for GET, 0:1 for SET
--hide-histogram \
--threads=<number_of_client_threads> \ # 1,2,4,...,64
--clients=<number_of_client_connections> \ # 10, 25, 40, 50
--requests=200000 --distinct-client-seed \
--data-size 256 --expiry-range=500-500 \
-s <host_of_dragonfly_server> \You can plug in different --proactor_threads values for Dragonfly and various --threads and --clients values for memtier_benchmark to repeat the benchmark. We reached 6.43 million ops/sec with 64 Dragonfly threads, 64 memtier_benchmark threads, and 40 client connections.
Conclusion
In this blog post, we have discussed how Dragonfly can automatically and fully utilize the hardware it operates on by leveraging the thread-per-core model and shared-nothing architecture. With the latest benchmark results, Dragonfly again stakes its claim as the most performant in-memory data store on earth. Not just the number, but the overall design and architecture give developers even more confidence in Dragonfly's ability to handle the most demanding workloads.
Feel free to check out our GitHub repository, documentation, and get started with Dragonfly by running it locally with Docker using one single command. Happy building, and stay tuned for more updates in 2024!

{kind=link}
{kind=link}