Dragonfly's New Sorted Set Implementation
This blog post dives into Dragonfly's innovative approach to enhancing the sorted set data type, showcasing a new B+ tree implementation that significantly reduces memory usage by up to 40% and improves performance.
March 14, 2024

Background
Redis offers a plethora of data types to cater to various use cases. Among these, sorted set stands out as a unique and powerful data type. Unlike traditional hash tables in Redis, which store unordered collections of strings, sorted sets maintain their elements in ascending order based on a score or lexicographic order. This inherent ordering capability, combined with the flexibility of non-repeating members, makes sorted sets an invaluable tool for tasks like leaderboards, time-series data, and priority queues.
In the process of working closely with our community and customers to constantly improve Dragonfly, we identified some inefficiencies with the Redis implementation of sorted sets. We decided the best way to address this was to rebuild sorted sets from scratch. In this article, I will explain how we went about doing this.
TL;DR
- We built a new sorted set implementation based on the B+ tree that significantly reduces memory and improves performance; see benchmark results.
- Starting with Dragonfly v1.9, this was an experimental feature.
- Starting with Dragonfly v1.11, the feature is stable and enabled by default.
- In Dragonfly v1.15, the original sorted set implementation from Redis was removed.
When Tax is Bigger Than Payment
Around eight months ago, when I was inspecting the memory usage profile for one of our cloud customers, I noticed their memory usage seemed too large for the number of entries they stored. On further inspection, I noticed that this particular customer used sorted sets, and specifically, they had many sorted set entries with many thousands of members in each one of them.
When we first launched Dragonfly, we reused most of the existing Redis data structures and instead focused on design changes first: multi-threading, transactional support, and replication. Once we achieved stability with our core features, we decided to dive in and analyze the Redis sorted set implementation.
Underneath, Redis utilizes a data structure called skiplist to store entries in a sorted set when it surpasses 128 elements.1 During my analysis of Redis's skiplist implementation, I observed that, on average, it requires 37 bytes per entry in addition to the essential 16 bytes for storing the entry itself. The 16 bytes are essential since for one entry in a sorted set:
- The
memberis a string, which requires an 8-byte string pointer.2 - The
scoreis a double-precision floating-point number, which also requires 8 bytes.
# Using the ZADD command to add a member with its score to a sorted set.
ZADD key score memberThis can also be observed in the simplified Redis skiplist node structure below. We will come back to this definition later in the blog post for more details.
// Assuming 64-bit systems, the pointer size is 8 bytes.
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // member (or element), pointer to an SDS string, 8 bytes
double score; // score, double-precision floating-point number, 8 bytes
// ... // other fields, additional metadata
} zskiplistNode;This 16-byte size, as needed to store and point to the actual data, is a theoretical lower bound for a single entry in a sorted set. On top of that, additional metadata is necessary in the data structure to maintain the sorted order of these entries. I will refer to the sorted set entry as a (member, score) pair to emphasize the 16-byte memory usage when necessary.
For instance, for an entry with a field length of 16 characters, Redis stores 32 bytes of useful data, containing 16 characters of string and the 16-byte (member, score) pair, plus an additional 37 bytes for skiplist metadata. This results in more than a 100% tax! And it is a fairly common use case as well, since when using sorted sets, we tend to store things like IDs in them instead of string blogs that are too large.
Of course, such overhead isn't problematic if justified and comparable to other implementations' overhead per entry. Frankly, I wasn't sure what to expect, as I hadn't kept up with the latest developments in this area. However, a Google search led me to a C++ project named cpp-btree. My tests showed that this implementation could achieve as little as 2 bytes of overhead per entry, which was promising! Their design uses a classic B-tree, but they attained remarkable memory efficiency through 'bucketing'—a technique commonly used in advanced hash tables. This technique involves grouping multiple entries in a single tree node, significantly reducing the metadata overhead per entry. This project has since been integrated into the Abseil C++ library, which Dragonfly also utilizes.
Skiplist vs. B-tree
To understand the differences between skiplist and B-tree approaches, we first need to understand the skiplist design. A skiplist consists of multiple layers of linked lists. The bottom layer is a standard linked list containing all items. The layer above it is sparser, containing approximately half the items. Each successive layer contains half the number of items as the layer immediately below it. The additional layers above the bottom one act as express lanes to speed up the lookup operations and to provide O(log N) complexity on average.
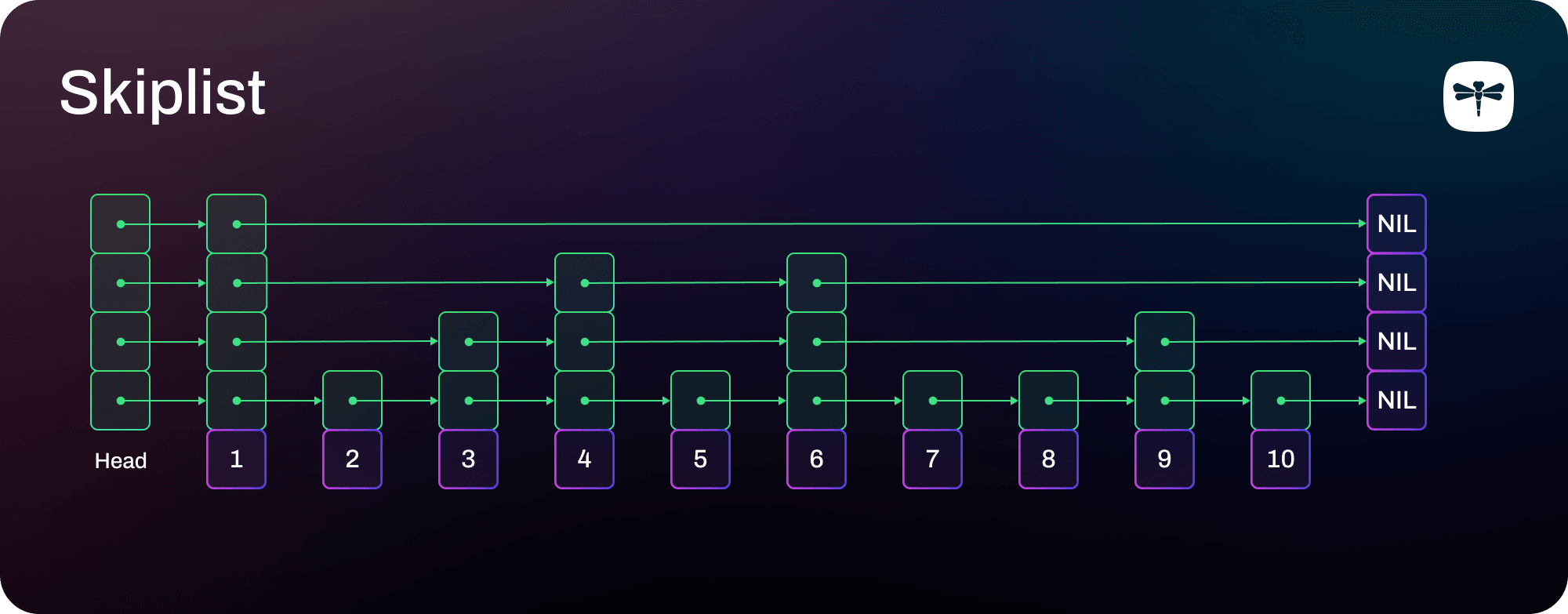
The complete Redis skiplist node looks as follows:
// Assuming 64-bit systems, the pointer size is 8 bytes.
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // member (or element), pointer to an SDS string, 8 bytes
double score; // score, double-precision floating-point number, 8 bytes
struct zskiplistNode *backward; // backward pointer, 8 bytes
struct zskiplistLevel {
struct zskiplistNode *forward; // forward pointer, 8 bytes
unsigned long span; // typically 8 bytes
} level[]; // variable size, but at least 1 level
} zskiplistNode;The allocation of the level array is determined by the node's position in the structure, as depicted in the diagram. A node always requires at least one level, but it may have more to be part of those sparser express lanes. Essentially, a node comprises a 16-byte (member, score) pair, a backward pointer for the linked list (8 bytes), and a level array (16 bytes x the number of levels it reaches). To sum up, a node will occupy:
- A minimum of 40 bytes (i.e., nodes
2, 5, 7, 8, 10in the skiplist diagram) - Every second node of 56 bytes (i.e., nodes
3, 9in the skiplist diagram) - Every fourth node of 72 bytes (i.e., nodes
4, 6in the skiplist diagram) - And so on…
In Dragonfly code specifically, the allocator adjusts allocation sizes to multiples of 16 bytes, so the minimum size of a skiplist node in Dragonfly is 48 bytes.
So where does the average of 37 bytes of overhead come from? A 37-byte overhead means that the average total size of an entry is 37 bytes + 16 bytes for the (member, score) pair, or 53 bytes. Based on the knowledge we have about Redis skiplist nodes, we can compute the expected weighted average of 4 entries in a skiplist (i.e., nodes 2, 3, 4, 5 in the skiplist diagram):
(48 + 56 + 72 + 48) / 4 = 56 bytes per entryThis computation is close enough to the empirical evidence we got.
In contrast, a B-tree holds multiple elements within each node. The cpp-btree design utilizes a 256-byte node array capable of containing up to 15 (member, score) pairs.
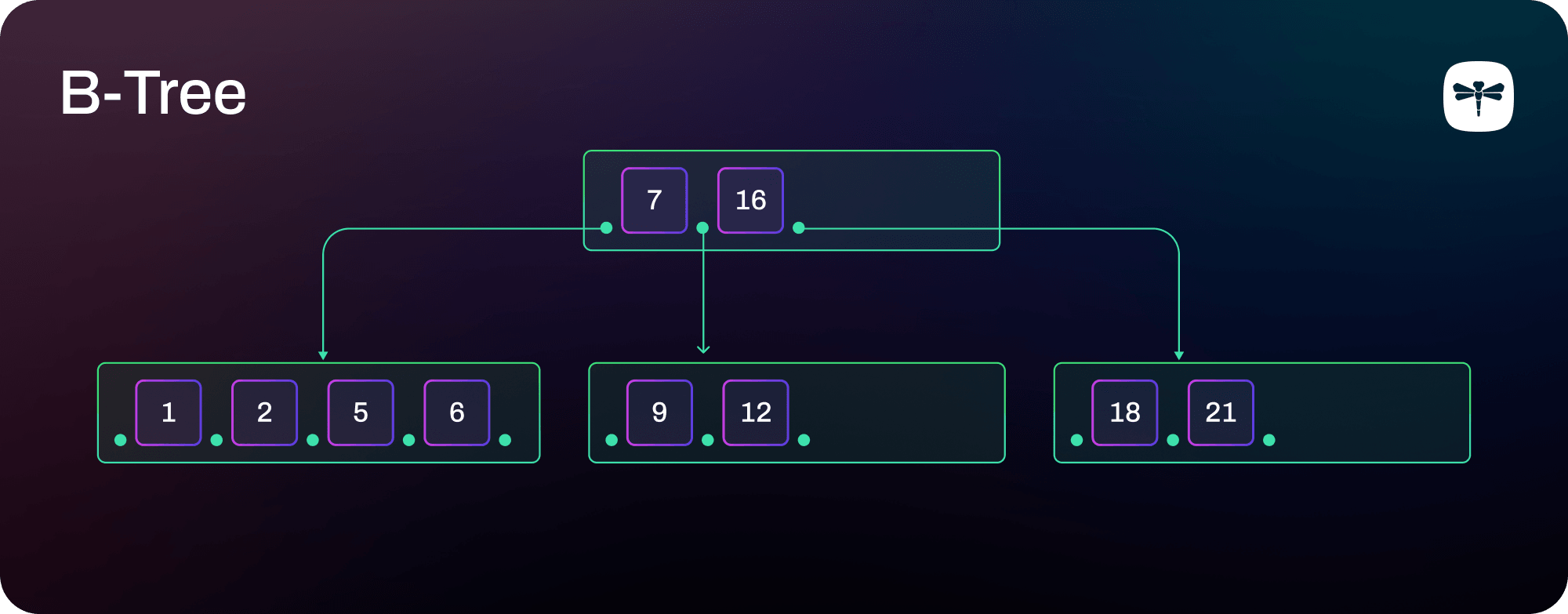
This implies that the branching factor for such a tree ranges from 7 to 15. For example, with 1000 entries, at least 67 leaf nodes are required, plus 5 to 10 inner nodes, which amounts to:
77 nodes x 256 bytes/node ÷ 1000 entries = 19.2 bytes per entryThis translates to an average overhead of 2 to 3 bytes per entry, depending on the load of the inner nodes.
I Know What You Did Last Summer
Unfortunately, my excitement was a bit premature because the Redis sorted set API requires custom functionality around its ranking API. This is not something standard B+ trees provide out of the box, and cpp-btree is not an exception. Without support for the ranking API, I would not be able to implement ZRANK and similar commands that need to compute the rankings of the elements quickly.
There was no easy way to add the ranking API to cpp-btree without intrusive changes, so I decided to implement the Dragonfly B+ tree as a side project. It went faster than anticipated, since we did not need to implement a fully generic tree. Instead, we only needed an implementation tuned to Dragonfly use-cases. At the end, we achieved the expected 2-3 bytes overhead on average per entry, compared to 37 bytes overhead with the original skiplist implementation. Our implementation is also faster, which becomes significant when running queries on really large sorted sets of orders of tens of thousands or even more.
Benchmark Results

We used the redis-zbench-go tool to benchmark sorted sets.3 Redis and Dragonfly both have sorted set implementations that employ listpacks for sets with lengths up to 128. However, when it comes to longer sets, Redis switches to a skiplist implementation, while Dragonfly utilizes its aforementioned B+ tree implementation. To comprehensively evaluate performance across these configurations, we devised two distinct loadtest profiles: ZADD (10-128) and ZADD (129-200).
The ZADD (10-128) profile sends 1 million ZADD commands, each containing 10 to 128 elements. On the other hand, for the ZADD (129-200) profile, we dispatched 800k commands, with each containing 129 to 200 elements to servers under test. For both profiles, we first ran them on Redis v7. Then, we run them on a Dragonfly instance using only one thread, namely Dragonfly-1, to show how it compares with Redis. Finally, both profiles were run on Dragonfly with eight threads, namely Dragonfly-8, demonstrating its vertical scalability when more CPUs are available.
Please note that the CPU performance of both Redis and Dragonfly sorted set implementations is dominated by other CPU-intensive tasks that backends need to perform in order to process a request. Hence, the impact of CPU optimizations on overall throughput is limited in these tests.

Sorted Set Throughput: Redis v7 vs. Dragonfly with 1 Thread & 8 Threads
As you can see, Dragonfly in single-threaded mode can sustain a little bit higher throughput, but the nice thing about it is how it scales vertically efficiently, reaching 4-5x on 8 threads. Please note that the initial motivation for building better sorted sets was memory efficiency, and higher QPS is just an added bonus. The next graph demonstrates the memory usage of all servers after all the commands were sent.
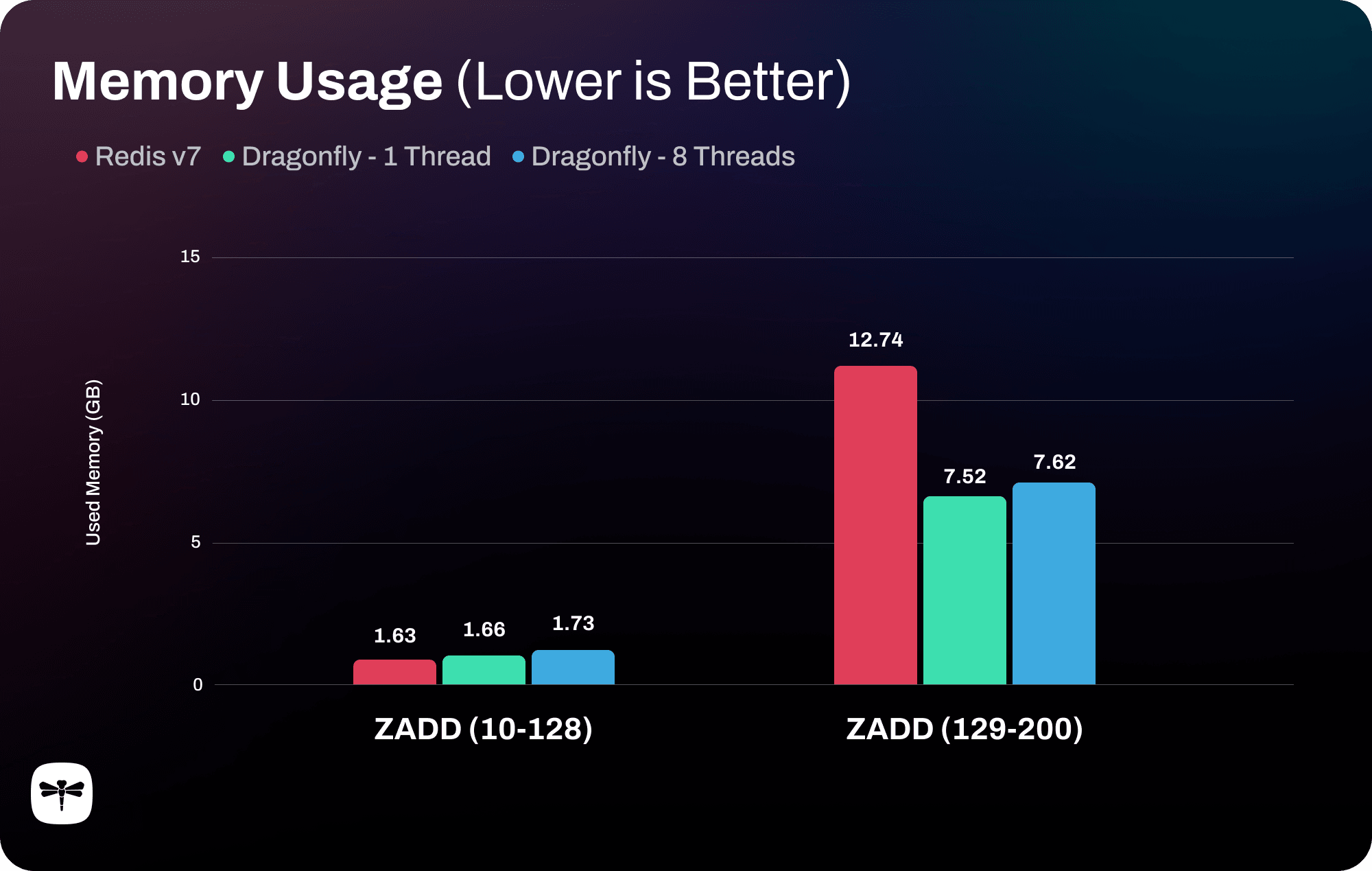
Sorted Set Memory Usage: Redis v7 vs. Dragonfly with 1 Thread & 8 Threads
As you can see, ZADD (10-128) does not show any difference in memory usage. It is expected given that Dragonfly uses the same listpack data structure for small sets like Redis. However, with large sorted sets, Dragonfly is much more efficient in terms of memory usage. One can observe up to 40% memory reduction when using Dragonfly. There is not much difference between using multiple threads and a single thread in this case.
Conclusion
In this blog post, we've journeyed through the innovations taken by Dragonfly in enhancing the efficiency of sorted sets, a fundamental data structure that can support various use cases such as leaderboards, time-series data, and priority queues.
Dragonfly initially concentrated on pivotal architectural design choices, adopting a multi-threaded, shared-nothing model and leveraging Redis's existing data structures to establish a solid foundation. The innovation never stopped, and we've evolved beyond these beginnings with the introduction of a new sorted set implementation based on B+ tree. This advancement significantly enhances memory efficiency and represents Dragonfly's ongoing commitment to pushing the limits of being the most advanced in-memory data store.
Take our word for it, but also try it out by deploying a Dragonfly instance to see for yourself how Dragonfly is setting new standards in data structure optimization and performance enhancement.
- For small collections (hashes, lists, sorted sets with a small number of elements), Redis uses a very memory-efficient encoding called listpack that just stores all the elements of such a collection in a single blob, serialized linearly one element after another. Listpack is indeed very memory efficient, but it has terrible
O(N)access complexity, thus fitting only for collections with a small number of elements. Before Redis 7.0, another encoding called ziplist was used for small collections. ↩ - The string pointer in this context is a pointer to the Redis Simple Dynamic String (SDS) data structure, which is a much more efficient and flexible alternative to the standard C string. ↩
- Commands for benchmarking using
redis-zbench-go:
# Redis, ZADD (10-128)
redis-zbench-go -mode load -r 1000000 -p 6379 -key-elements-min=10 -key-elements-max=128 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore # Query
# Redis, ZADD (129-200)
redis-zbench-go -mode load -r 800000 -p 6379 -key-elements-min=129 -key-elements-max=200 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore # Query
# Dragonfly, 1 Thread, ZADD (10-128)
redis-zbench-go -mode load -r 1000000 -p 6379 -key-elements-min=10 -key-elements-max=128 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore # Query
# Dragonfly, 1 Thread, ZADD (129-200)
redis-zbench-go -mode load -r 800000 -p 6379 -key-elements-min=129 -key-elements-max=200 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore # Query
# Dragonfly, 8 Threads, ZADD (10-128)
redis-zbench-go -mode load -r 1000000 -p 6379 -key-elements-min=10 -key-elements-max=128 -c 160 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore -c 160 # Query
# Dragonfly, 8 Threads, ZADD (129-200)
redis-zbench-go -mode load -r 800000 -p 6379 -key-elements-min=129 -key-elements-max=200 -c 160 # Load
redis-zbench-go -mode query -r 1000000 -p 6379 -n 10000000 -query zrange-byscore -c 200 # Query