Why Does Dragonfly Require Only Half the Infrastructure of Redis?
Dragonfly's innovative architecture, data structures, and advanced features can significantly reduce infrastructure needs, delivering substantial cost savings.
September 10, 2024

Introduction
When it comes to managing large in-memory datasets in the cloud, cost efficiency is a crucial factor. Through a pricing analysis[^1] of monthly costs below, as well as previous blog posts (#1, #2), we've found that using Dragonfly can lead to at least 40% cost reduction compared to Redis or Valkey-based cloud services. These savings are especially impactful as datasets scale.
Data Size | Dragonfly Cloud | Redis Cloud Cache | AWS ElastiCache |
|---|---|---|---|
100GB | $900 | $1684.8 | $1707.9 |
400GB | $3,600 | $6739.2 | $6831.4 |
So, why does Dragonfly offer significantly lower costs than other solutions? That's the question we're here to answer today. In this blog post, we'll explore the key innovations behind Dragonfly, including its architectural design, performant and memory-efficient data structures, and the new SSD data tiering feature. These advancements allow Dragonfly to operate more efficiently, reducing memory usage, infrastructure costs, and operational costs—whether you're running in the cloud or on-premises. Ultimately, the efficiency of the software determines how much hardware you need, making Dragonfly a cost-effective choice across all environments.
Architecture: An Overall Cost-Efficient Design
Multi-Threaded & Shared-Nothing Architecture
Dragonfly is not a fork of Redis but rather a completely new design that leverages a multi-threaded, shared-nothing architecture. This modern architecture enables Dragonfly to fully utilize the capabilities of multi-core hardware in cloud environments. As a result, Dragonfly can scale vertically by efficiently managing resources. On a single AWS c7gn.16xlarge server instance, Dragonfly is able to reach 6.43 million ops/sec and up to 1TB of in-memory data. If that's not enough for you, Dragonfly Cluster is also going to be available soon for horizontal scalability.
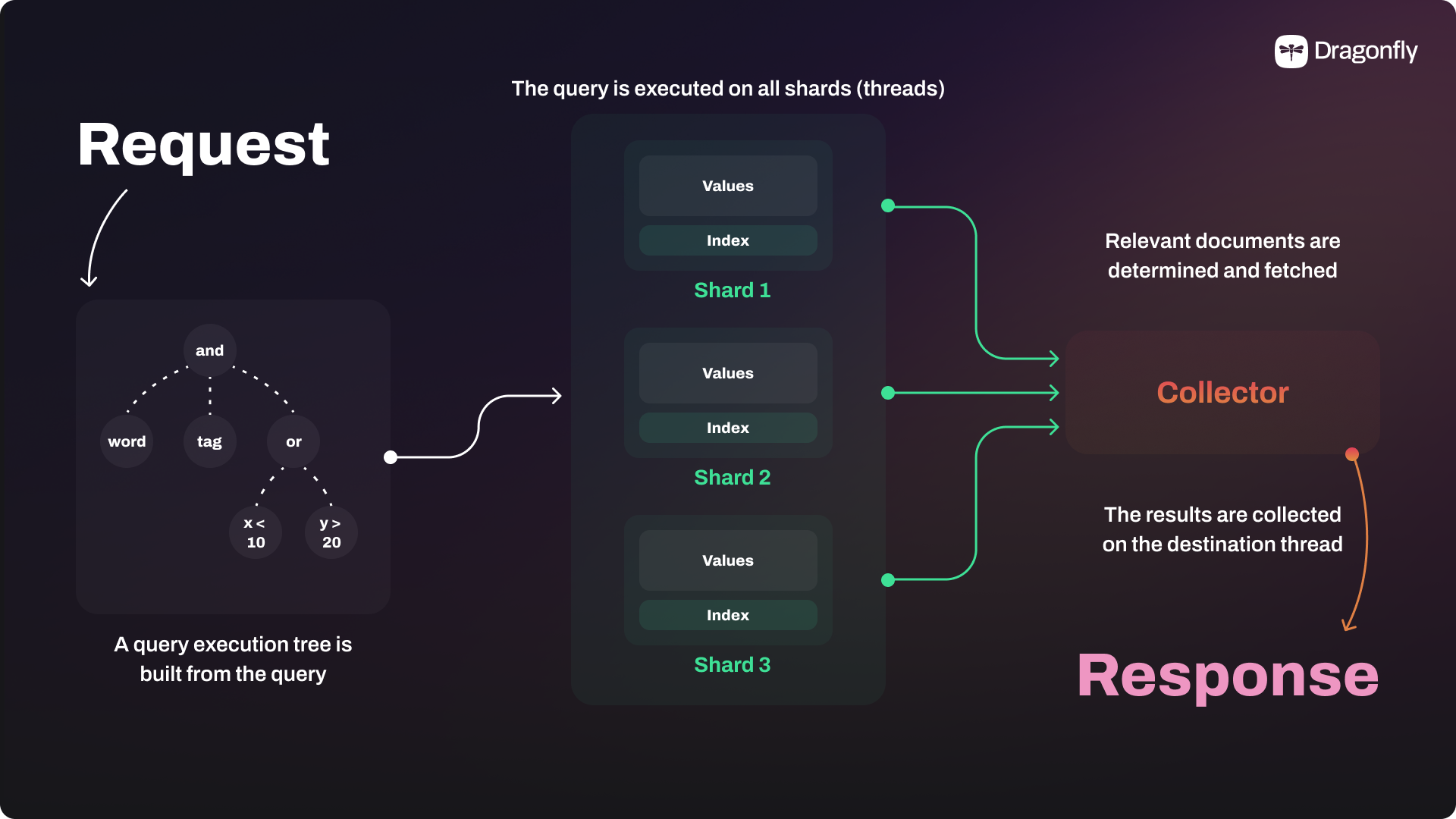
On the other hand, Redis relies on clustering and additional management layers to achieve scalability. Even on a single multi-core machine, clustering is needed for Redis to utilize the hardware resources. By avoiding the need for complex clustering, Dragonfly reduces operational overhead and simplifies management, resulting in lower infrastructure and operational costs.
Snapshotting Algorithm Advantages
Another significant cost advantage comes from Dragonfly's approach to snapshotting. Redis uses the fork system call to create snapshots, which operates through a copy-on-write mechanism. While this is totally a common approach, it has limitations, particularly in write-heavy workloads. As data is modified, the system must create additional memory pages, leading to memory spikes that can, in extreme cases, double the memory usage. To accommodate these spikes, developers and organizations often need to over-provision memory to avoid performance degradation or out-of-memory errors, which causes inflated costs.
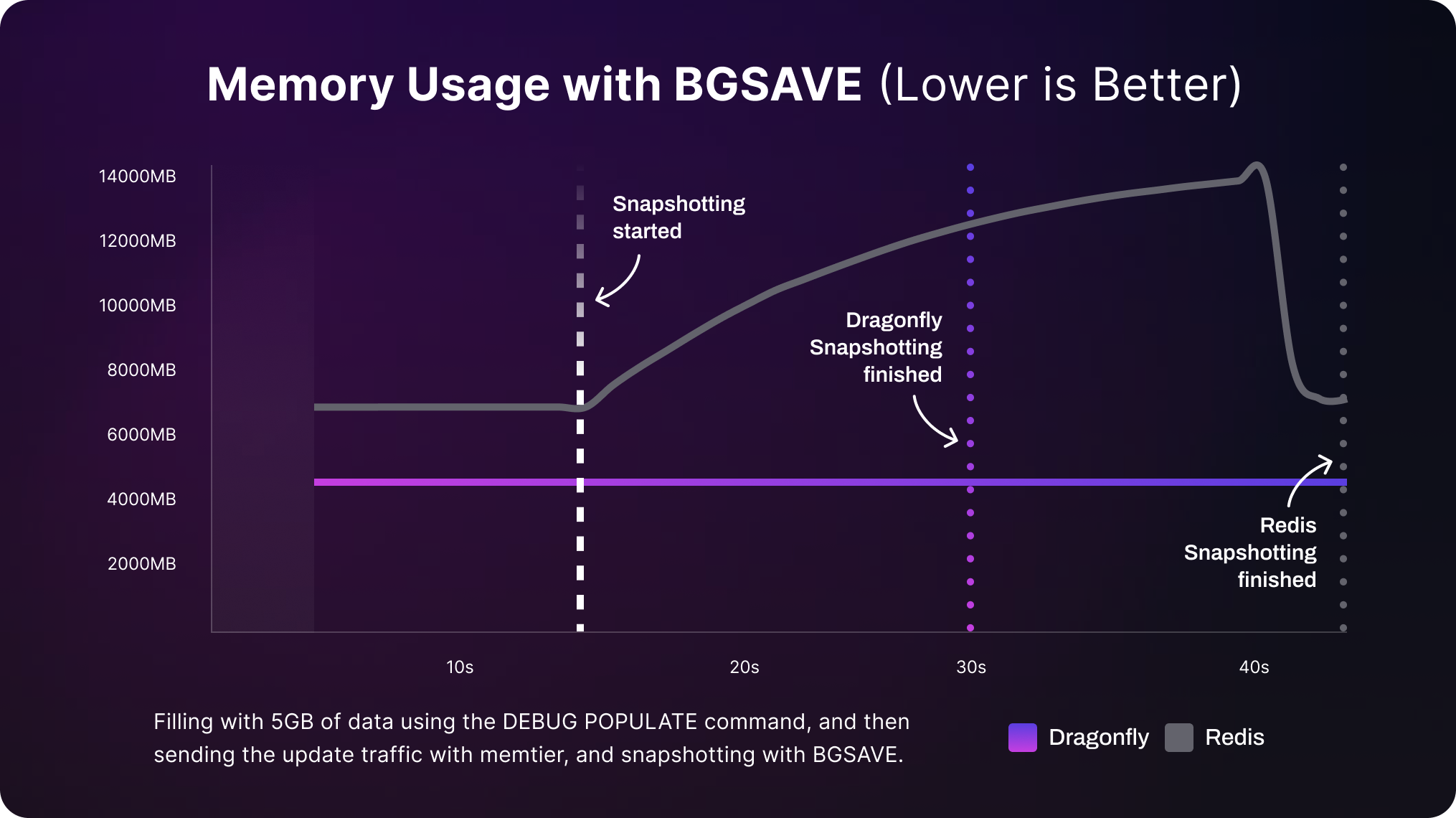
Dragonfly, on the other hand, adopts a more efficient snapshotting mechanism that avoids these memory spikes. By utilizing versioning and update hooks, Dragonfly marks changes in memory without duplicating data. This architecture ensures that memory usage remains stable during snapshots, even under heavy write loads, which eliminates the need for over-provisioning. With this approach, we can maintain optimal memory usage and reduce unnecessary costs—either on premise or in the cloud, memory is not cheap!
Data Structures: The Key to Memory & Cost Savings
Dragonfly's Dashtable vs. Traditional Hash Tables
Dragonfly's Dashtable offers significant advantages over Redis's traditional hash table in terms of memory efficiency and performance. While Redis relies on two hash tables per dictionary, resulting in an overhead of 16–32 bytes per item and memory spikes during resizing, Dragonfly's Dashtable avoids this by using a segmented, constant-size hash table approach.
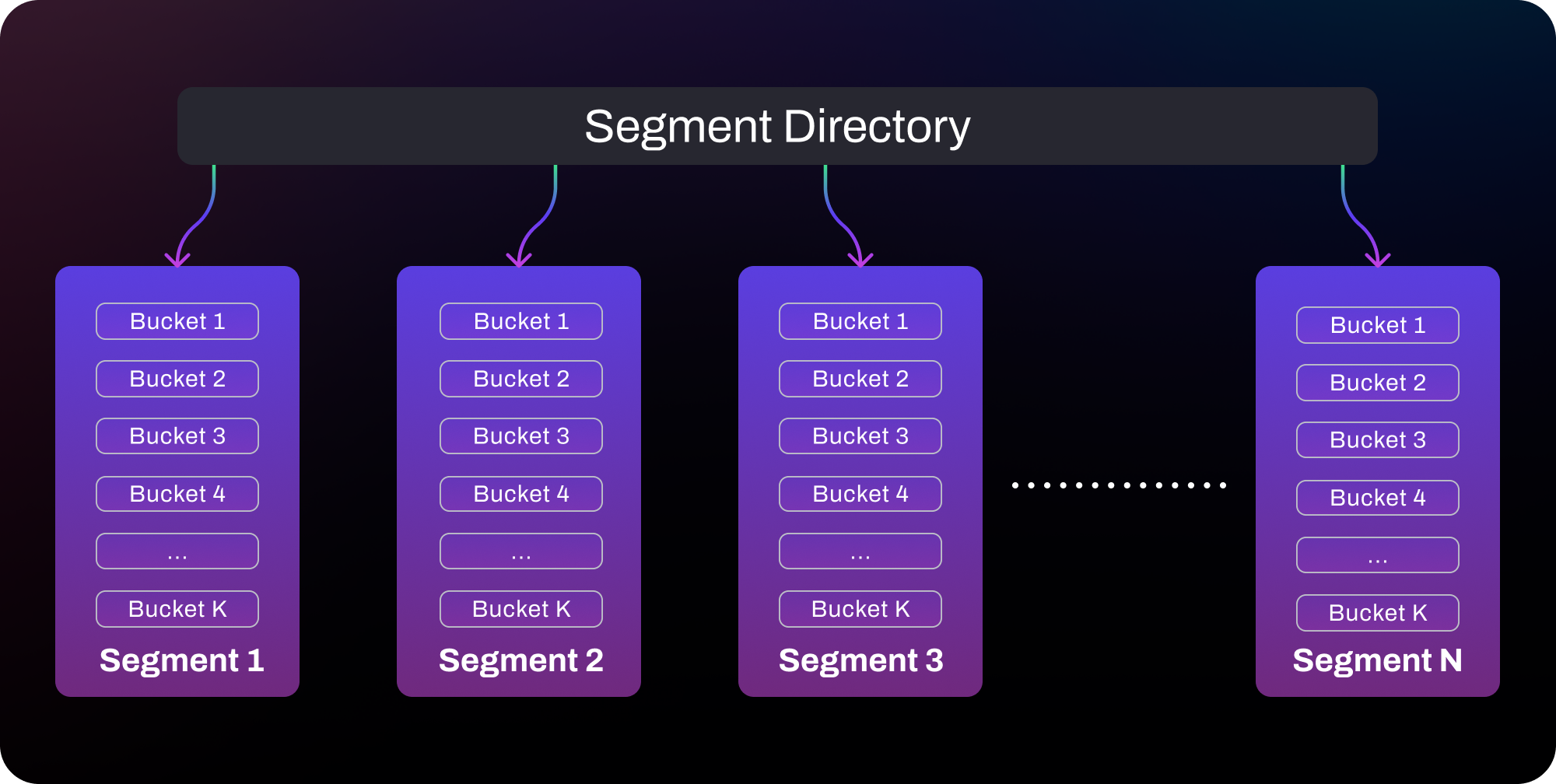
As a Dashtable grows, it splits individual segments without requiring a full table resize, reducing memory usage to 22-32 bytes per item with only an overhead of 6-16 bytes. With reduced overhead, Dashtable can lower memory usage by over 40% in certain cases. This again gets rid of the need for over-provisioning and reduces latency spikes. Additionally, Dragonfly's open-addressed hashing is more friendly for CPU cache, further enhancing performance on modern hardware. This efficiency reduces both memory and compute costs, making Dragonfly a more cost-effective solution for managing large-scale, in-memory data. If you are interested in more details, check out our documentation on Dashtable internals.
Dragonfly's B+ Tree-based Sorted Sets
Dragonfly replaces Redis's skiplist for sorted sets with a B+ tree implementation, which reduces memory usage and improves performance. In Redis, skiplist can incur an overhead of ~37 bytes per entry beyond the necessary 16 bytes for storing the sorted set element and score. Dragonfly's B+ tree, on the other hand, packs multiple elements into each node, reducing the overhead to just 2-3 bytes per entry. Additionally, the B+ tree scales well with multi-core systems, enabling higher throughput when handling large workloads.
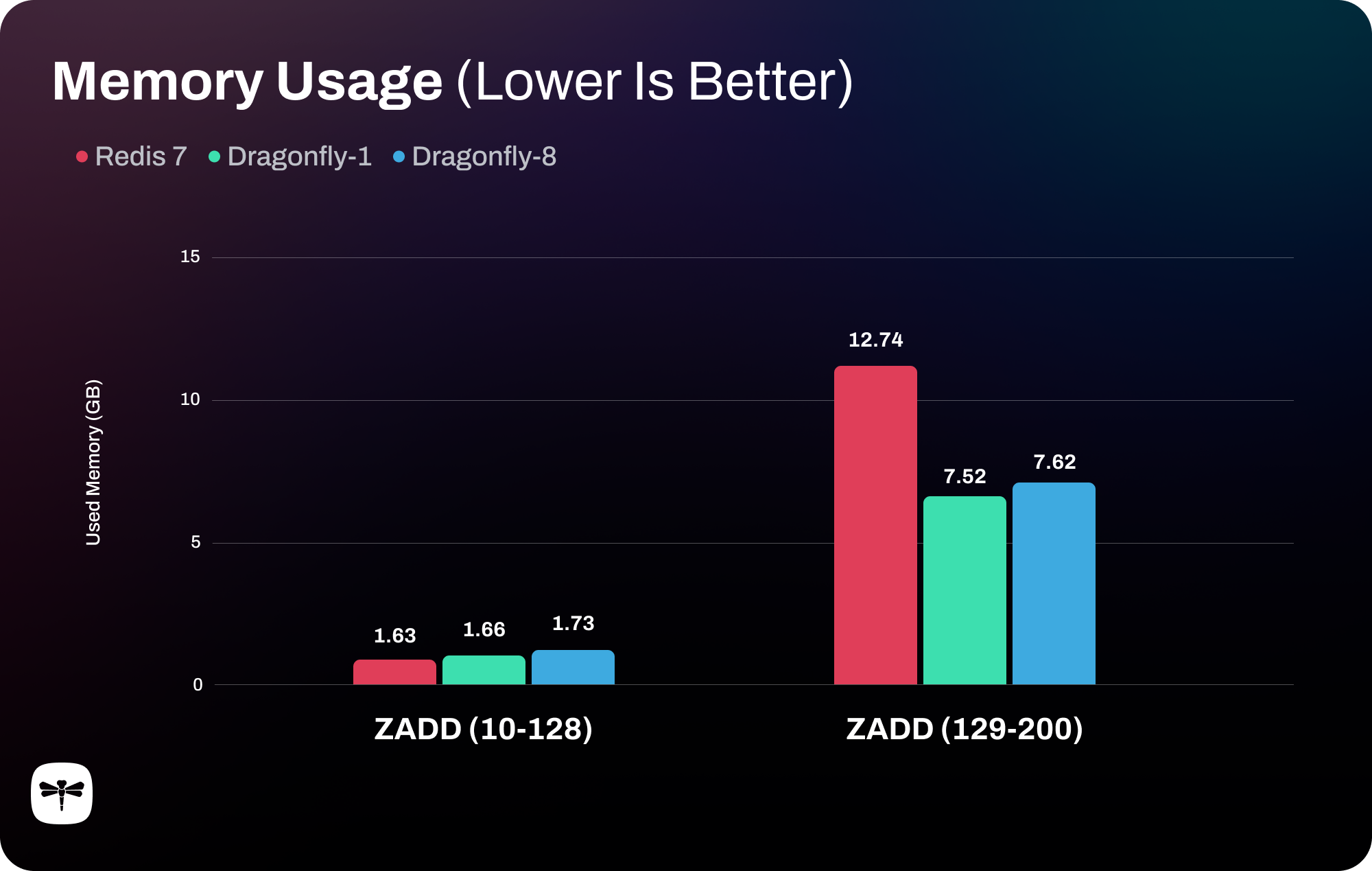
Sorted Set Memory Usage: Redis v7 vs. Dragonfly with 1 Thread & 8 Threads
In the example above, we compared the memory usage of Redis v7 and Dragonfly with 1 and 8 threads for sorted sets. The "ZADD (10-128)" profile sends 1 million ZADD commands, each containing 10 to 128 elements, which would not use Redis skiplist nor Dragonfly B+ tree, since for a sorted set with less than or equal to 128 elements, both data stores use a data structure called listpack2. On the other hand, for the "ZADD (129-200)" profile, we dispatched 800k commands, each containing 129 to 200 elements. Surpassing the threshold of 128 elements, Redis uses skiplist, while Dragonfly uses B+ tree to store the sorted set. And as we can see, Dragonfly demonstrates up to 40% memory reduction and major throughput benefits for sorted sets.
SSD Data Tiering: The New Cost-Cutting Edge
Last but not least, Dragonfly's new SSD data tiering feature, recently introduced in v1.21, offers a cost-effective way to manage large datasets by offloading less-frequently accessed data to SSD storage. With this feature enabled, String data can be moved from memory to SSD while keeping frequently accessed hot data in memory, optimizing memory usage without sacrificing performance. This allows Dragonfly to maintain high throughput and sub-millisecond latency, even with the reduced reliance on expensive RAM.
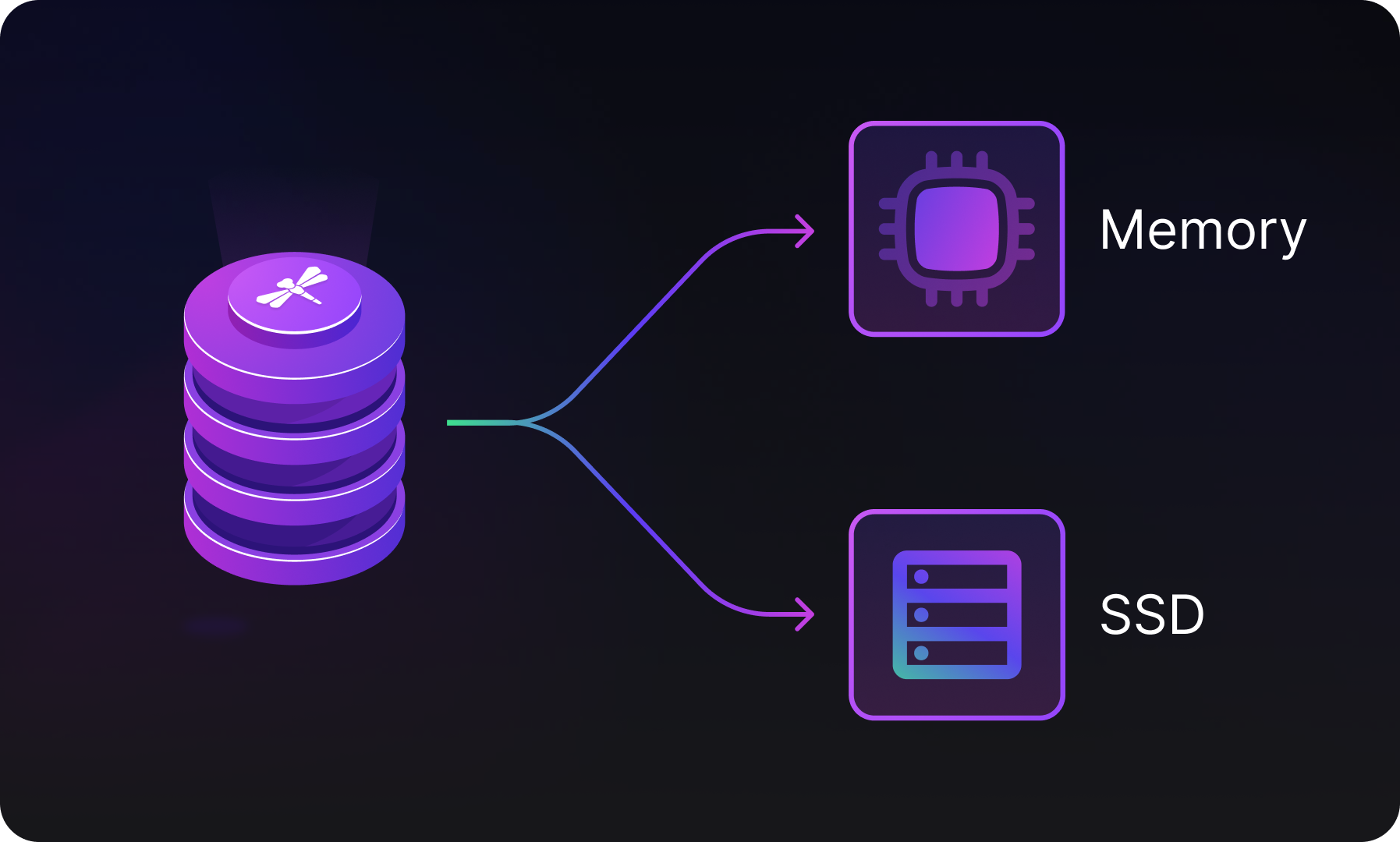
SSD tiering provides significant cost savings by leveraging the lower cost of SSD storage while still offering fast data access for most operations. This approach is ideal for applications with large datasets that exceed available main memory, as it allows efficient scaling without requiring expensive memory upgrades for the hardware. By combining in-memory speed with SSD capacity, tiered storage offers a balanced, cost-effective solution for managing large data volumes.
Ready to Experience Dragonfly Yourself?
As outlined in the introduction, Dragonfly offers substantial cost reduction compared to Redis or Valkey-based services. This cost advantage is driven by Dragonfly's innovative architecture, efficient data structures like Dashtable, which can reduce memory usage by up to 40% in certain cases, and the B+ tree-based sorted sets, which also show up to 40% memory reduction in the scenarios we discussed above. While these optimizations vary depending on the use case, and we cannot simply add these numbers together, the overall infrastructure cost consistently results in at least 40% reduction. When taking operations per second (ops/sec) and other pricing factors into account, Dragonfly can sometimes lead to up to 80% cost reduction compared to other solutions. Advanced features such as SSD data tiering further contribute to this efficiency, with even more improvements to come in the future.
By utilizing Dragonfly's cutting-edge design, you can scale your applications without compromising on performance or breaking the bank. Whether you're managing high-throughput workloads or looking to optimize storage costs, Dragonfly is a powerful, cost-effective alternative to Redis. Get started with Dragonfly Cloud today or explore our documentation to unlock the next level of efficiency for your data infrastructure.
- Pricing data is based on September 2024 for the North Virginia region across all services. No replication or high-availability configurations were selected for any of the services.
- Dragonfly Cloud: We used the standard instance type, selecting the memory size directly to determine the cost.
- Redis Cloud: The pricing was calculated using the Pro tier, which allows for larger instance sizes. Default settings for cache were applied, and we selected the memory size while keeping the default operations per second (ops/sec) configuration.
- AWS ElastiCache: We used one standard
cache.m6g.8xlargeinstance for the 100GB scenario and four of these instances for the 400GB scenario to determine pricing.
↩
- For small collections (hashes, lists, sorted sets with a small number of elements), Redis uses a very memory-efficient encoding called listpack that just stores all the elements of such a collection in a single blob, serialized linearly one element after another. Listpack is indeed very memory efficient, but it has terrible
O(N)access complexity, thus fitting only for collections with a small number of elements. Before Redis 7.0, another encoding called ziplist was used for small collections. ↩

{kind=link}
{kind=link}
{kind=link}
{kind=link}